

The quantity of data being generated continues to significantly increase which is driving the need for ongoing expansion and investment in network monitoring, security and analytics systems. Cubro’s solutions are able to reduce the quantity of data generated and stored for network monitoring, security and analytics use cases while retaining all of the required data – this approach is able to reduce the capacity and footprint required of network tools and associated data lakes and has significant benefits in performance, CAPEX and OPEX, and power and space consumption. This blog describes the associated challenges and solutions.
Managing data retention in large-scale systems poses several challenges. Here are some of the critical challenges associated with data retention in such environments:
1. Storage Capacity: Large-scale systems generate and accumulate vast amounts of data over time. Ensuring sufficient storage capacity to retain this data can be a significant challenge. It requires a scalable and cost-effective storage infrastructure that can handle the volume, velocity, and variety of generated data.
2. Data Lifecycle Management: Data retention involves managing the entire data lifecycle, including its creation, storage, access, and eventual disposal. Handling data at scale requires well-defined policies and processes for data classification, archival, and deletion. Implementing effective data lifecycle management practices becomes complex when dealing with massive volumes of data.
3. Data Accessibility and Retrieval: With vast amounts of data stored over time, retrieving specific information becomes challenging. Efficient indexing, search capabilities, and metadata management are necessary to enable quick and accurate data retrieval when needed. Designing and maintaining robust data retrieval mechanisms in large-scale systems can be complex and resource-intensive.
4. Cost Management: Data retention involves storage and ongoing operational expenses. As data volumes grow, so does the cost of storage infrastructure, including hardware, software, and maintenance. Balancing the need for retaining data with cost considerations becomes crucial to avoid excessive expenses.
Addressing these challenges requires robust technical solutions, effective policies and procedures, and a clear understanding of the organisation’s data retention requirements.
Efficient Data Retention Management with Cubro Solutions
Cubro offers some effective solutions to solve these issues.
Filtering on non-relevant traffic:
Data retention requires effective filtering to ensure that only relevant information is stored and maintained. Cubro Content Filtering solution leverages cutting-edge Deep Packet Inspection (DPI) techniques to filter data based on its content or metadata.
Did you know that over 70% of internet traffic comprises video and audio content from trusted platforms like Netflix and YouTube? While this traffic holds no value for data retention and LinkedIn (LI), it still consumes valuable storage space and resources.
To address this challenge, Cubro has developed an advanced application filtering solution specifically designed for large and high-volume networks. Our solution enables you to filter out non-relevant traffic efficiently, ensuring that only meaningful data is retained.
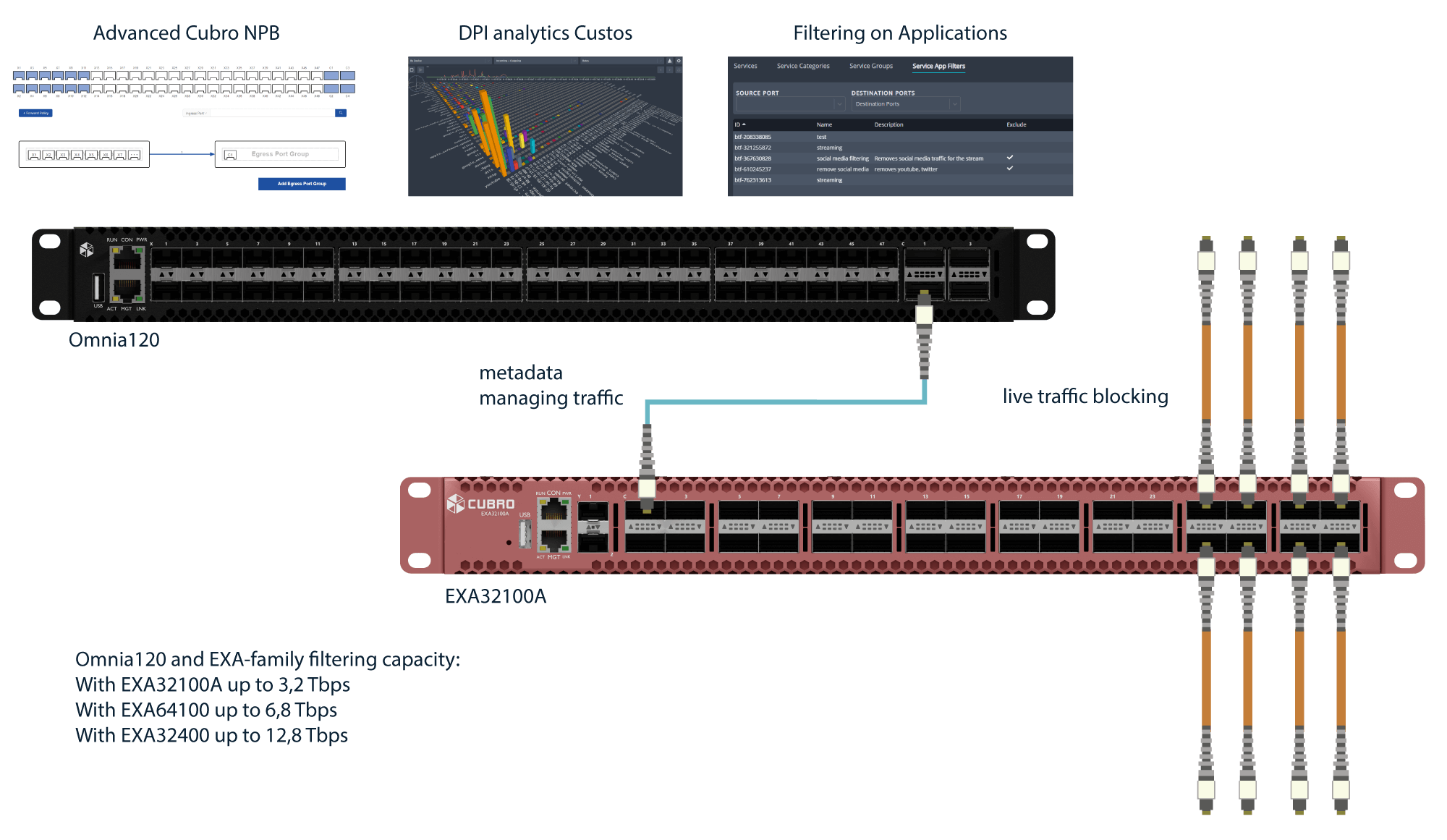
With this solution, the traffic bandwidth can be reduced by 60% to 70% compared to a complete capture solution. This means much lower cost and longer retention time.
To further reduce the footprint, we propose utilizing a more efficient analytic approach as the second solution – Time Window-Based Monitoring.
In the context of data retention, it is unnecessary to examine each individual TCP/IP session associated with a service session. In today’s WEB 2.0 traffic landscape, a service session, such as streaming a Netflix video or browsing on Amazon, does not rely on a single user-to-server connection. Rather, it encompasses multiple TCP/IP connections.
For instance, when streaming a Netflix video, 50 or more TCP/IP connections may be established and distributed across various servers and different data centres, potentially even spanning other locations worldwide. The information obtained from retaining data related to these multiple TCP/IP sessions is minimal since the traffic is SSL cyphered, making it inaccessible to anyone other than the service provider. Additionally, the messages and protocols employed within these services frequently change. However, traditional data retention solutions continue to operate based on the retention of these TCP/IP sessions.
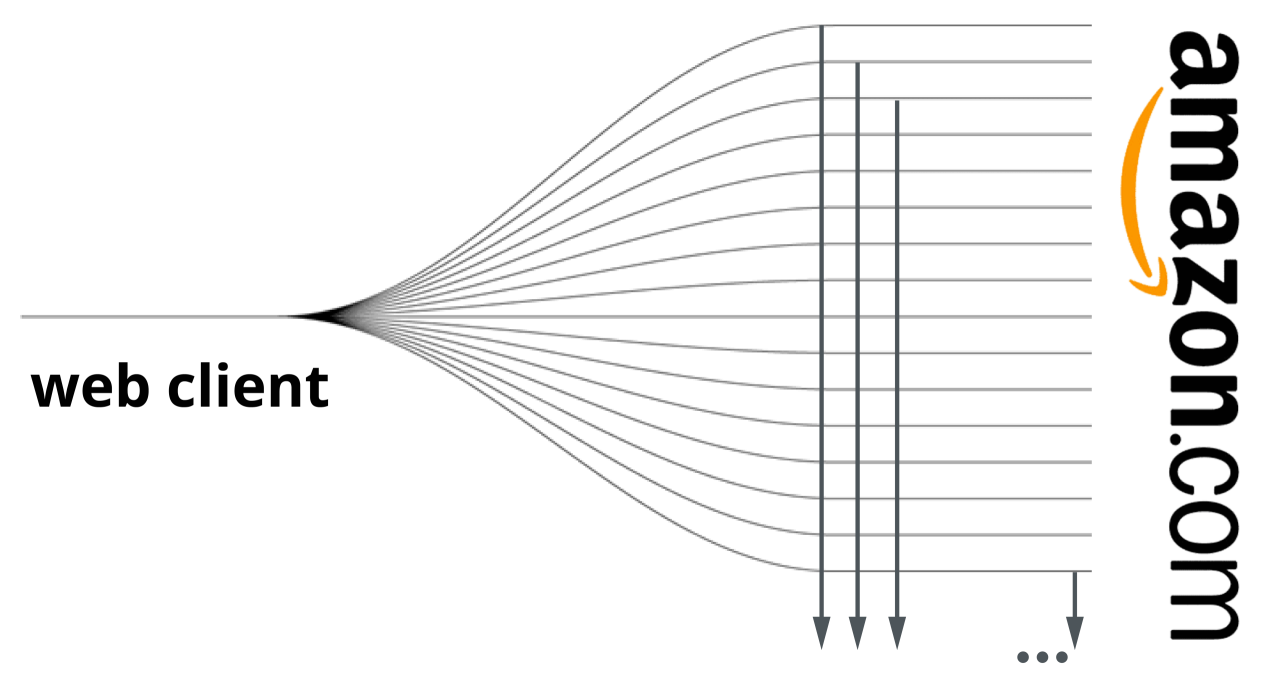
For each 5-tuple connection, one NetFlow Call Detail Record (CDR) is generated. However, many of these CDRs cannot be detected as Amazon related because the external domain cannot be resolved.
After the flow is generated, it is forwarded to the Flow Cache. A Flow Cache can accommodate a substantial number of entries, ranging from hundreds of thousands to millions. It’s worth considering that this process consumes memory resources.
When the flows expire, they’re exported to the NetFlow Collector, which will constantly analyse and archive them for future reference.
The Cubro way uses DPI signatures to combine all the flows in one single flow.

For each client, there is a bucket for each application, if needed, and we collect/count all packets for a specific time window (configurable). When the window is closed, an XDR is produced/enriched and sent out. The advantage is that the traffic is reduced by 90% and avoids constraints and performance issues in the workflow along to the Data Lake.
This new Cubro solution makes a huge difference to the cost of storing the data, but retrieving the data is much faster. See the table below.
In the below table, you see a TCP/IP flow-based storage calculation. For one TB/sec, traffic input and 90-day retention would require 29 PB storage. This is a small data centre.
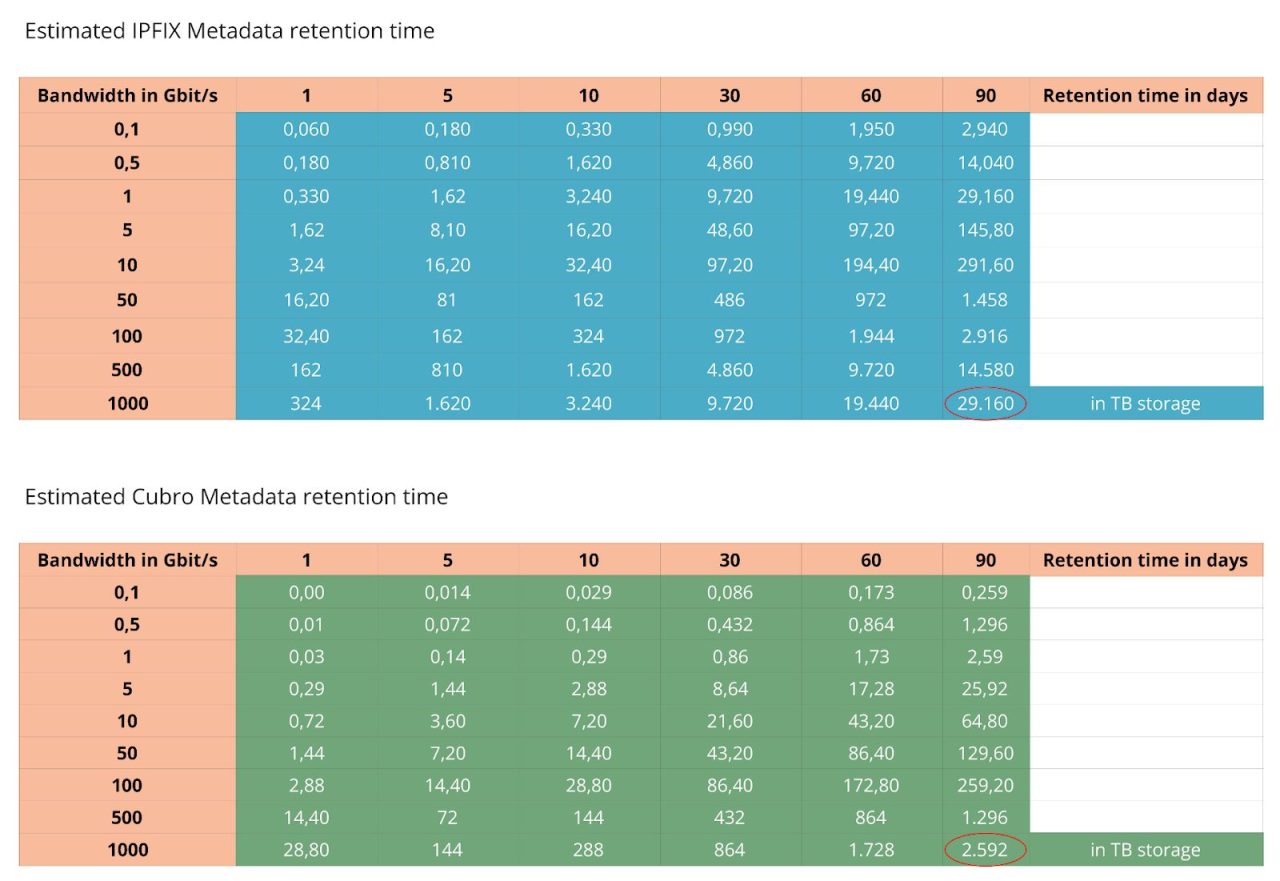
The Cubro solution now needs only 2,5 PB which is easily achievable with a data lake.
An optimal solution is when both approaches are combined, reducing the data by filtering first and then using the Cubro CDR.
This would result in 750 TB per 1 Tbit/s traffic input.
Use cases supported by Cubro CDR
Bandwidth Monitoring – Cubro CDR enables monitoring of bandwidth information per subscriber per application with a remarkable 1-second resolution. This high-resolution granularity is crucial for capturing real-time insights into network traffic patterns and ensuring accurate analysis of bandwidth consumption.
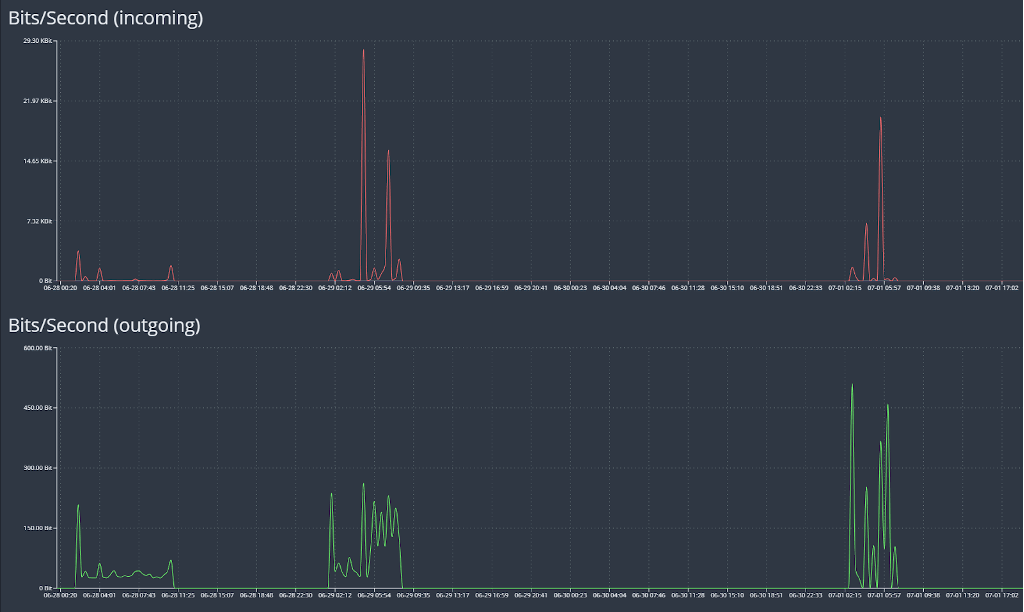
Subscriber Traffic Analysis: The accompanying image illustrates the efficiency of Cubro CDR. For instance, consider the WhatsApp traffic of a specific subscriber. The red graph represents incoming traffic, indicating a bandwidth of 29 kbps, while the green graph displays outgoing traffic with a mere 500 bytes. This indicates that the subscriber primarily receives messages (red) while the green traffic represents the handshake with the server where the message is received. This is just one example of how Cubro CDR provides efficient and detailed insights into subscriber traffic behaviour.
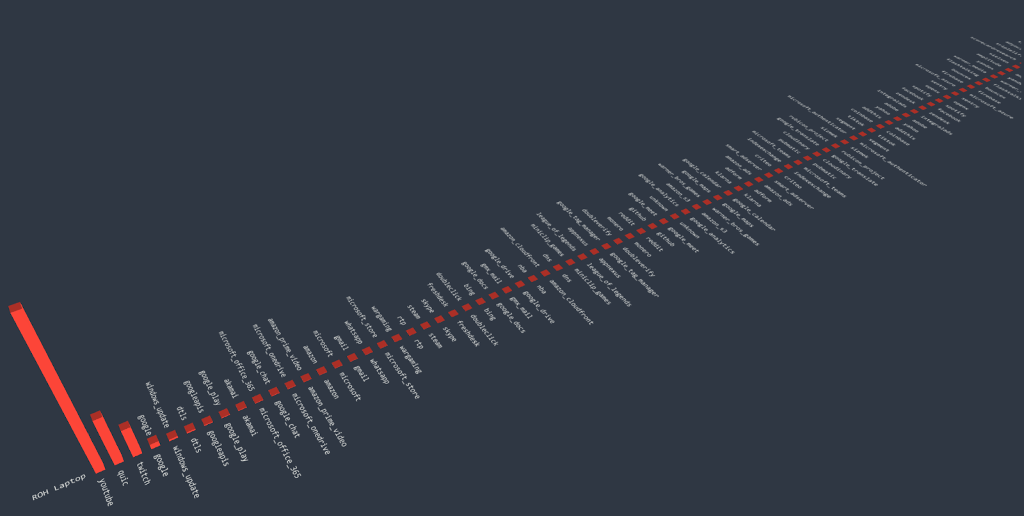
This graph shows the application one subscriber uses in a certain time frame.
Additional options to reduce the footprint:
Cubro understands that filtering may not always be an option, especially when customers want to observe all applications. To address this, we have developed a solution that aggregates services into groups. This approach significantly reduces the output of CDR and lowers the overall cost of data storage in the data lake.
Alternatively, we can reduce the output to events over time for specific applications, providing information on which applications were used during specific time frames without including bandwidth details. This flexible approach caters to diverse data retention requirements while optimizing storage efficiency.
Innovative Hardware Design

Cubro’s solution stands apart by leveraging ARM-based smart NIC cards, which are developed in-house. By moving away from traditional Intel Server Hardware, we significantly reduce the footprint in terms of cost, size, and energy consumption. This innovative hardware design ensures a compact solution that occupies only 19U of rack space while handling input rates of up to 2 Tbps.
Summary
As the quantity of data increases then the challenges associated with its retention, access performance and costs continue to increase. Cubro’s solutions deliver new, innovative ways of addressing these challenges to improve performance, reduce CAPEX and OPEX, and reduce power and space consumption.